Table of Contents:
- Introduction (1/11)
- Goals and Architecture (2/11)
- The inotify API (3/11)
- File Watcher, C++ (4/11)
- File Watcher, Bash (5/11)
- Execution Engine (6/11)
- Containerization (7/11)
- Kubernetes (8/11)
- Demo (9/11)
- Conclusion (10/11)
- System Setup (11/11)
- Source code
Introduction
This post will discuss the high level goals of the system and the architecture required to achieve them. These are generally pretty straightforward: if you look at a site like ideone, which is a front-end to a multi-language compiler system, what are some of the features made available? What information does the back-end need from the front-end in order to carry out its task?
It is easy to see what sort of information is transferred over when using ideone. After typing in some code, providing stdin input, and hitting “Run”, you can see what information is being sent over from the front-end. There are a lot of unknown/irrelevant fields, a few interesting ones like timelimit and note, which have corresponding front-end fields in the “more options” link on the page, and of course, the source code (file), stdin (input) and language (_lang) fields, all of which are required to properly construct the code on the back-end and run it.

The inputs to this system will be very similar to ideone – after all, you can’t have a working multi-language compiler system without being able to get the source code, console input, and target language. That said, the goals that we would like to achieve are listed below:
Goals
The user is able to:
- Provide source code for a supported language
- Provide command-line arguments for their program
- View any console output that their program writes
- Have an interactive session with the program: allow for runtime console input
The system provides:
- An environment capable of taking input code and compiling (or interpreting) it
- A (mostly) sandboxed environment where the code will run
- A mechanism to capture the output of the program
- A mechanism to provide input to the program
- A (very basic) degree of resiliency and scalability
Taking these goals one at a time, lets discuss what is needed on the implementation end to achieve them.
Provide source code for a supported language
It is assumed that this is a given: a user has written code in a language and the system has this made available to it in order to compile/execute the provided code.
Provide command-line arguments for their program
This is relatively straightforward given that we have the code to execute. Command line arguments can be forwarded if we choose to execute the code via the terminal, or can be provided programmatically via execv or similar means if there is a dedicated process responsible for running the code.
View any console output that their program writes
This is also pretty straightforward as there are built-in ways to do this: the output can be redirected if the program is executing via the terminal, or it can be redirected programmatically with a little more work.
Have an interactive session with the program: allow for runtime console input
This is the most challenging part of the system as this requires state to be maintained between the user and the executing program. There needs to be a way to simulate the two-way interaction between a user and the executing program for this to work. The program-to-user path is a bit simpler and is just the previous goal above. The user-to-program path the the difficult one because it will require forwarding input at runtime to the program. That means that there needs to be a way to directly connect to the stdin of the executing program. This is generally a pretty complex and error prone task. The approach taken by this project will be to execute the program in a pseudoterminal, which is just one approach of many.
High-level architecture
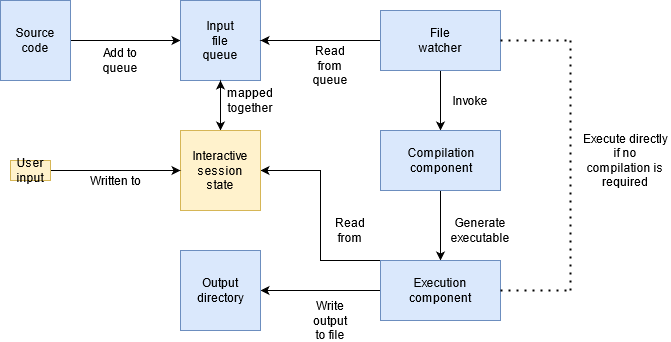
At the topmost level, the design is pretty simple. The user’s source code get added to a file queue which then gets picked up by a monitoring process. This monitoring process then forwards the file to the compilation and/or execution components. The code is then executed and its output is captured and written to an output directory. There is a bit of extra work done to support interactive sessions, mainly around keeping the session state active somewhere. This session state will be the user input, which the execution component will monitor and forward to the running executable.
There are a few things here that merit more in-depth discussion though. For one, how is the input file queue and interactive session state implemented? As always, there are many different approaches here, but for the sake of simplicity, these will just be folders with files in them in the implementation. The file watcher process will monitor this folder for changes and pick up any input files that have been placed into it. Similarly, the execution component will monitor the folder for session state and forward any changes in the state file to the running executable. The input file and interactive state need to be kept track of together as the state will be required by the executable generated from the input file.
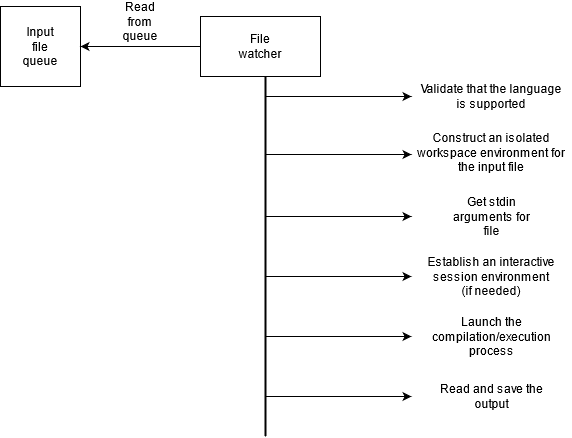
The file watcher component is the most complicated part of the system. There is a lot of work that will go in to taking the source code and making it ready for compilation. There are a lot of considerations that need to be taken. A few of the key ones are listed below:
- What happens if the input file is for an unsupported language?
- How will the user be notified if there is a compilation error?
- How will the user be notified if there is a runtime error?
- On a successful execution, how do we map the output file to the original source code?
- Should multiple files be processed at the same time?
- If multiple files are being processed, how will conflicts be avoided, i.e. how to prevent one compilation process from interfering with others?
In this implementation, unsupported language files will just be ignored. As far as compilation and runtime errors go, these can just be captured and written to the output file. Mapping output to input source code files should be pretty straightforward. We will assume that each language file has a unique name made of up the name plus the file extension, i.e. 123.cpp, abc.py, test.java, etc. We can generate an output file whose name is the input name plus a new extension, i.e. 123.cpp-output.log, abc.py-output.log, test.java-output.log.
Processing multiple files is an interesting challenge and a fun feature to add. There is nothing that should prevent multiple files from being compiled and executed at the same time, aside from system resources, i.e. RAM and/or CPU limits. Being able to execute in parallel should greatly speed up the overall system, at a minimal implementation cost. Instead of processing one input source code file at a time, these files – when added – can be dispatched to a thread pool where the processing takes place. However, to do this, there needs to be a way to isolate the compilation process of individual files. We want to avoid scenarios where two separate files exist in the same compilation path and might have conflicts when intermediate files are generated or cleaned up. To avoid this problem, each input file can have a dedicated workspace directory created for it from which the compilation and execution process will happen.
The diagram below summarizes at a high level how the file watcher component will work.
The other complex component in this system is the execution component. Although more lightweight than the file watcher, there is some logic that is worth explaining. The execution component is responsible for two main tasks:
- Launch the generated executable, capture its output, and write it to a file
- Feed user input to the running executable on stdin
As mentioned before, there are lots of different ways to capture a processes output. The approach taken here will be to launch the executable as a child process and capture its output via a pseudoterminal. Likewise, input can also be provided via the pseudoterminal connection. These tasks will be accomplished by the combination of the forkpty and execv functions.
The diagram below summarizes at a high level how the execution component will work.

The next series of posts will go into the concrete implementation of the file watcher and execution components.